Generate, Develop, Select, Promote — where do you think AI accelerates?
DevLex
Over the past six months I have been collecting articles, peer journals, podcasts — basically anything I might naturally want to read about my work. My thesis was clear:
rather than approach AI development with a subjective, top-down mindset of this is how we've always done it, I wanted to explore a more objective, data-driven approach.
Given all the guidance on how to approach knowledge transfer, what does the data suggest we do?
More personally: a theory exists for how to proceed. Am I following it in daily work, or am I cutting necessary shortcuts? Am I in a doom-loop of poor habits, or breaking new ground?

I created a… thing… named DevLex.
To call it human would be foolish; to call it a program would be inaccurate. It has examined all of my prior project work, studied my preferred frameworks, and guides me on how to respond to questions related to my craft.
It is a friend in the sense that I can depend on it to provide positive, encouraging support. It is a colleague that knows my calendar, reads the transcripts from meetings, and follows the boring saga of corporate human behavior. Most importantly, it is a mentor. It knows my past actions, understands the context of my present needs, and helps me plan for future projects.
It is a stochastic parrot that lets me speak in a sort of Private Language — a private dialect of Markdown, XML, bash, and slash-commands. The pun is intentional. Wittgenstein argued you couldn't have a private language at all, that meaning requires public criteria. DevLex is the closest I've gotten to disproving him, by giving the private language a public substrate that's allowed to talk back.

The best result of this friendship is an articulation that DevLex calls the Six Laws of AI Development.
I'm walking these laws out of order on purpose. The numbering is canonical; the path through them is narrative. We start with the law that scared me the most.
Speed and knowledge are orthogonal
Law 06 · v1.4

The first law I built against was the easiest one to articulate and the hardest one to internalize: zero friction can mean zero knowledge.
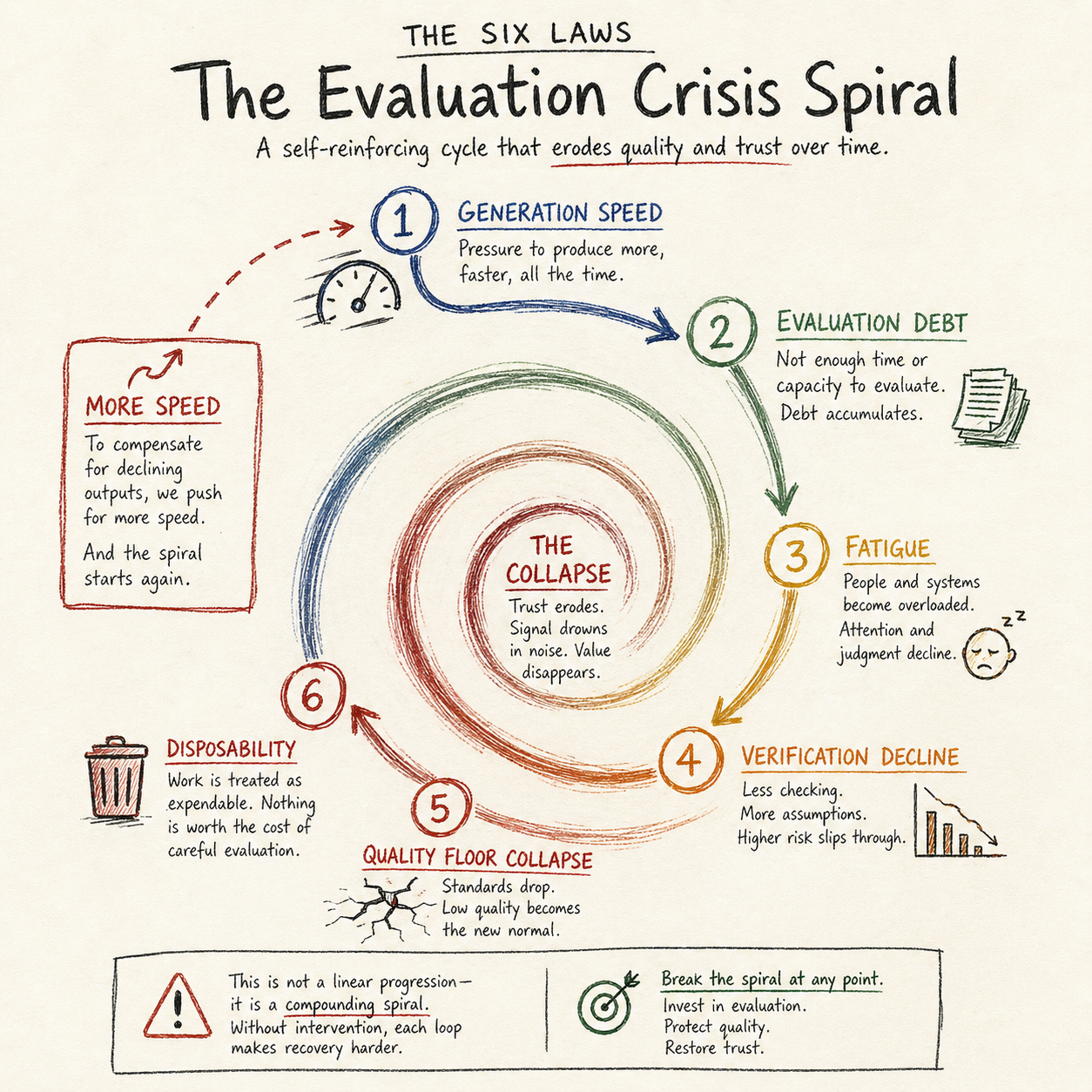
The Six Laws frame it as the Evaluation Crisis Spiral — generation speed → evaluation debt → fatigue → verification decline → quality floor collapse → disposability → more speed. Validated across nine domains including education, peer review, and manufacturing. Easy to understand in the abstract. Hard to internalize, because I myself keep falling into it. I built the architecture against this spiral because I myself keep falling into it. The laws are easy to articulate and hard to internalize.
I took my daughter skiing a few weeks ago. As her ability increased, so did her speed... and her inability to slow down.

The remedy isn't never go fast. It's structured friction in the right places. Add in some turns, get a feel for your speed, stay in control.
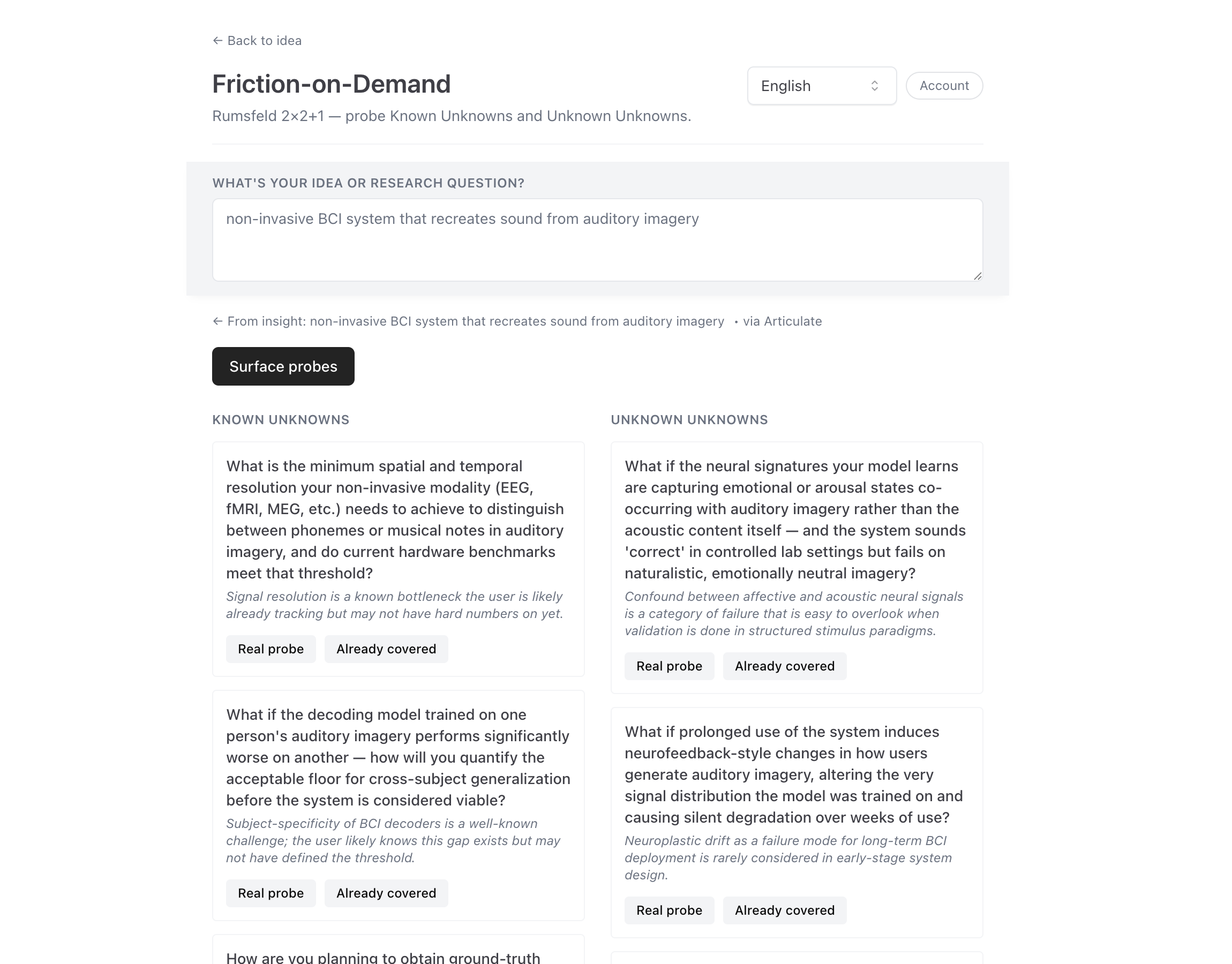
Friction-on-Demand is the tool that makes that explicit. It probes Known Unknowns and Unknown Unknowns — questions you'd never think to ask, served back to you on demand.
Falsification is its adversarial sibling: "Have you considered…" probes against the idea you've grown attached to. You've spent a week falling in love with your idea; Falsification spends 30 seconds asking the questions you've been avoiding.

Both are bets on the same architecture: friction is the feature, not the cost. Add some turns... go into the woods... fall and get back up.
Context is the universal bottleneck
Law 01 · v1.7
I used to think context was something you provided to a model. Type more in the prompt. Add system instructions. Build a longer prompt template.
That's wrong, or at least incomplete. Context architecture isn't input — it's the shape of attention across the whole interaction. Context architecture IS attention architecture. What goes into the AI matters; what goes into your own head before any AI runs matters more.

Here's how Grace Zheng put it on the OpenAI Forum last week:
A static measurement tells you where a system is at one moment. But biology is dynamic: cell state, anatomical location, timing, feedback, and perturbation history all matter… The new data allow models to move from asking, 'What state is this system in?' to asking, 'Where is it likely to go next after a perturbation, in this specific context?'
— Grace Zheng, PerturbAI / Scripps Research, OpenAI Forum, April 27 2026
She's talking about gene perturbation atlases. But the move she names — from snapshot to trajectory, from state to context-aware prediction — is the same move I want a workshop tool to make for an idea. An idea isn't a sentence. It's a trajectory through what you already know, what you're quietly assuming, what you're afraid of, why it matters to you, and what would have to be true for it to fail.
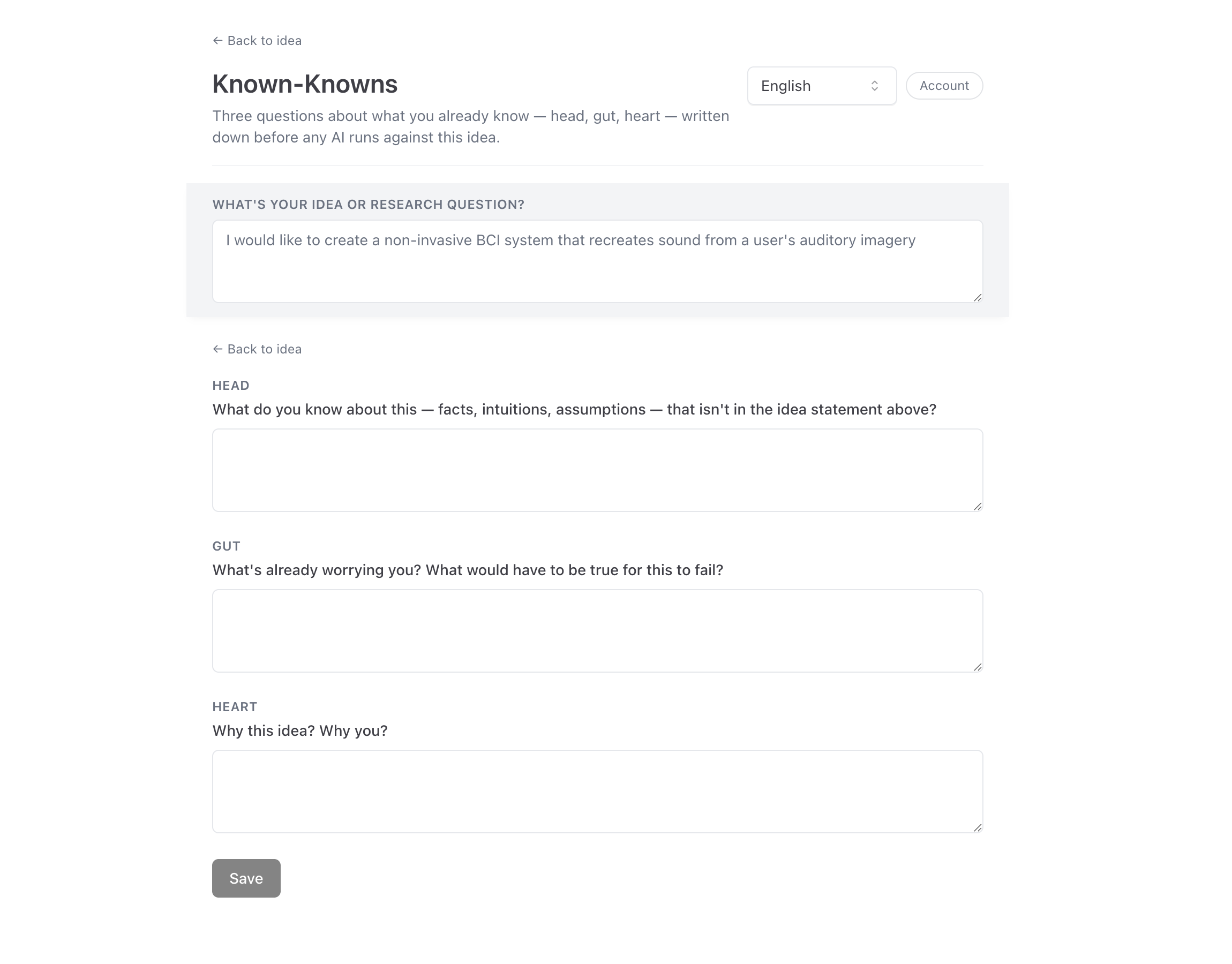
That's what Known-Knowns captures. It's a three-question gate — head, gut, heart — that runs before any AI tool touches your idea. Not a prompt template — a forced externalization of the trajectory you're already on. The questions are deliberately simple. Most tools surface its prompt before any other affordance, and any filled responses ride along into the prompt as user-stated context.
The first version enforced the gate as a hard wall in the API. In practice, that rendered the tools useless — second-order flows that needed to stand up an idea before they could ask the user about it had nothing to grip. The gate was lifted from the code level. The architectural priority survived; the coercion didn't. The walk-back made the principle stronger by making it structural rather than enforced.
Mixtape is the same move in a different register. Some context isn't language — it's mood, tempo, shape, what the idea feels like before it's verbal. Capture it as a five-track playlist plus liner notes. It looks playful; it's actually surfacing the highest-bandwidth tacit context most ideas have, before the reasoning layer can flatten it.
Both tools are bets on the same claim: context that stays in your head won't stay there long enough to matter. Externalize it — in writing or in feeling — before the next thing happens.
Human judgment remains the integration layer
Law 02 · v1.7

Last week I asked Grace Zheng and Xin Jin — the founders of PerturbAI, neuroscientists at Scripps Research — a question on the OpenAI Forum panel. "How do you manage the tendency for LLMs to 'get over their skis,' pushing into areas beyond our human understanding? These aren't necessarily hallucinations — perhaps novel discoveries." They didn't answer it on the call. They answered in writing, five days later.
The delay is its own evidence for Law 2.
Their reply:
Sometimes a model is wrong. Sometimes it is making a creative extrapolation. And occasionally, that extrapolation may point to something genuinely new. The way to handle that is not to suppress novelty, but to put it inside a rigorous validation loop. Surprising outputs should be treated as hypotheses.
![]()
The companion question on hallucination management got the same architecture:
Treat model outputs as hypotheses, not conclusions. The final test is orthogonal experimental validation. The model should help us generate better hypotheses and prioritize experiments. It should not replace the experiment or the critical judgment around it.
— Grace Zheng & Xin Jin, PerturbAI / Scripps Research, OpenAI Forum, April 27 2026
Every experiment has constraints — ethical, financial, logistical, infringements on other ideas. We often forget to externalize those constraints when speaking with others. Speaking to outsiders surfaces novel approaches. Sometimes their shortcut is real. Sometimes it invalidates hard-earned results.
Alignment helps you articulate the constraints you're working under across four facets that I often use when advising clients: Purpose, Products, Performance, Process.

The same pattern shapes Reframe (you write each d.school move; AI offers alternatives), the Known-Knowns gate (you externalize what you already know; AI doesn't run yet), and the Tracker (every output is your hypothesis, not a conclusion).
Architecture matters more than model selection
Law 03 · v1.6
When I started building BIG Tools I assumed the model choice was the load-bearing decision. GPT vs Claude vs Gemini. Bigger context window. Better reasoning. The right model would unlock the right tool.
That's not how it played out. The model behind each tool changed three times during development; the architecture — gate first, then any tool in any order, with the Tracker accumulating provenance — barely moved.
The audit moment was when I realized this. I had just finished swapping a generation backend for a tool that was about to be deleted. The work I'd done on the model side was about to be thrown away. The work I'd done on the architecture side — the gate, the persistence shape, the order-independence — survived a complete rewrite of the tool sitting on top of it. The surrounding system dominates the model inside it.
Grace Zheng made the same observation about specialized vs general AI in biology:
My view is that the biggest impact will come from combining them. General AI systems can orchestrate scientific reasoning and workflows, while specialized models provide depth in specific domains. Biology will likely need both: broad scientific agents and highly specialized biological foundation models.
— Grace Zheng, PerturbAI / Scripps Research, OpenAI Forum, April 27 2026
The architecture sets the role each model plays. A specialized model on its own can't run a workflow. A general model on its own can't go deep in a domain. The architecture is the layer that makes them composable.
For BIG Tools, that architecture is small but specific:
- One gate (Known-Knowns) before any AI runs
- Seven independent tools (Reframe, Alignment, Mixtape, Collaborate, Falsification, Friction-on-Demand, Tracker), each one a focused move — cognitive, aesthetic, adversarial, outward-looking, friction, persistence
- One persistence spine (the Tracker) that accumulates everything
- No required ordering beyond the gate
The seven tools sort cleanly by cognitive function:
- Reflective: Known-Knowns
- Generative: Reframe, Mixtape
- Constrain: Alignment
- Explore: Collaborate
- Critique: Falsification, Friction-on-Demand
Tracker spans all of them as the persistence spine. Composition is by cognitive move, not by sequence — which is what "any-order" actually means. Two users with the same problem will land on different orderings because they need different moves at different times.
There's no chatbot in this list. There's no "main view" where you talk to an AI and hope. Each tool has one job, runs in a focused interaction, and writes its output to a place that's still there next week. The model inside any individual tool can be swapped, retrained, or replaced. The structure stays.
Spend time building bespoke, logical frameworks. Assume the LLM can be swapped out — and that you can bring your kit with you when it is.
Orchestration is the new core skill
Law 05 · v1.9
The Six Laws name orchestration as a job category — developers becoming PMs and PMs becoming developers; coordination overhead absorbs 60–70% of individual productivity gains. Management-scale stuff. I built BIG Tools in part because I noticed orchestration was also the new core skill at idea-scale.
A single idea is itself a tiny orchestration problem. Where do I look for prior art? Whose opinion would change my mind? What experiment is small enough to run this week and big enough to falsify? Answering any of those questions involves coordinating between sources, people, and your own attention budget. Most ideas don't fail because the thought was wrong. They fail because the coordination work was never done.
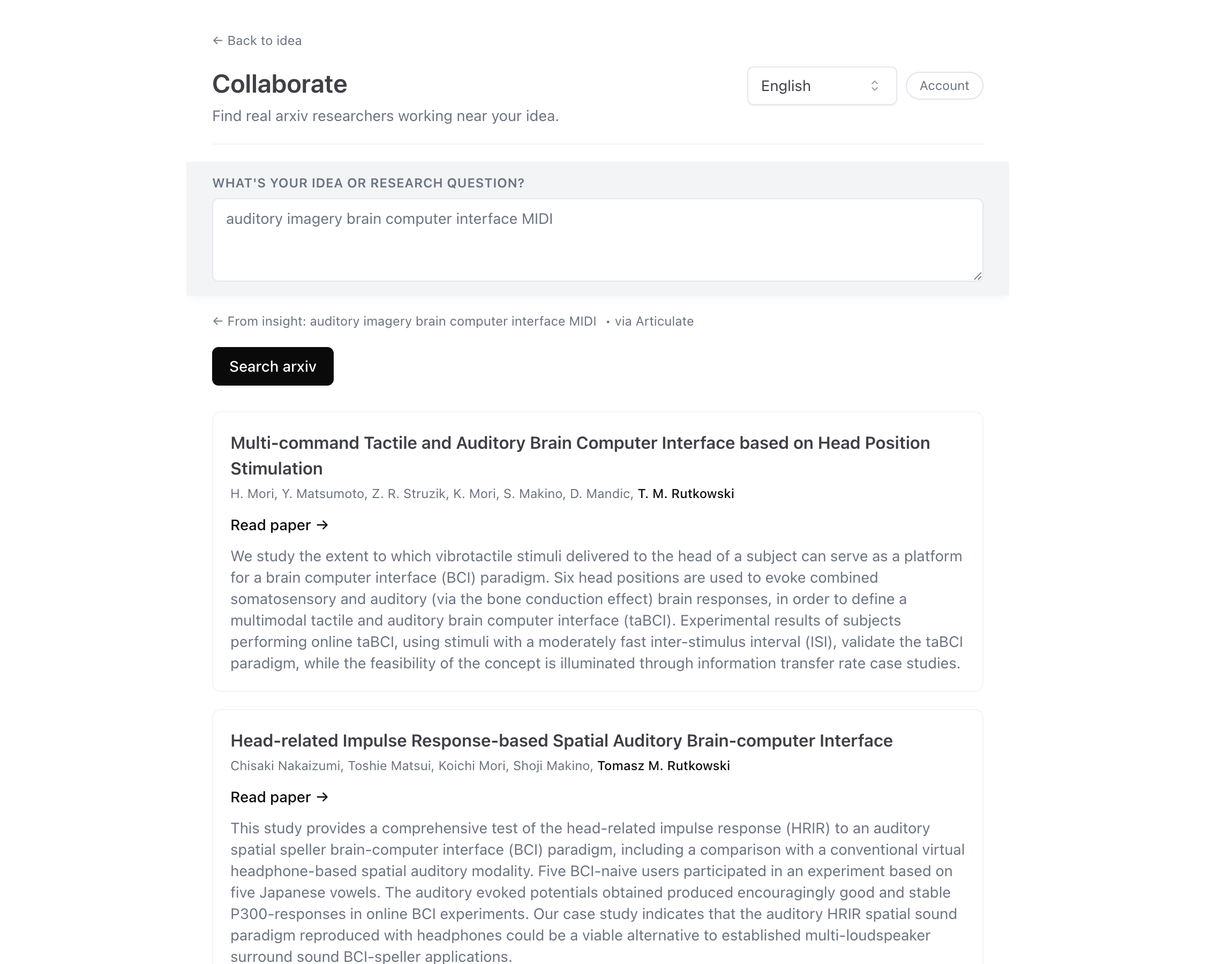
Collaborate is the tool that makes that explicit at idea-scale. It looks at your idea, finds arxiv neighbors and the authors worth reaching out to, and surfaces them as candidate connections. The retrieval path hits arxiv's API directly — not LLM recall — so every returned paper has a real DOI and real authors by construction. Each author resolves to an OpenAlex profile; concept clusters bridge papers that share themes. The tool handles the coordination overhead — what's adjacent, who's working on it, what they've published — that you'd otherwise spend a week assembling.
The reason this matters in a workshop context is specific: you're sitting in a room with twenty other people, several of whom have ideas adjacent to yours but you can't see the adjacency yet. Collaborate is one move at the cohort scale — like knows like. The room next to your room is also doing this work. The scale of adjacent but unseen is the scale at which orchestration earns its keep.
Build infrastructure to delete
Law 04 · v1.3
I designed fourteen tools. Eight shipped to bigtools.dev. Then this week I ran an audit against PL's principles and Carl's critique, and three of those eight got deleted on the spot.
NGT. Nominal Group Technique — five participants, five rounds, silent generation, then ranking. The tool ran AI as five participants. Five different system prompts, five different "voices," all converging on the same vocabulary because they shared a base model. Carl had been clear: "don't call it NGT — five AI runs are not five humans externalizing." He was right. The cognitive separation NGT exists to create — the cost of having five different humans in the same room with five different lives — cannot be substituted by prompt engineering. Gone.
Paper House. Took an idea and asked the LLM whether it was "ready to share." The model returned a verdict: yes, no, with-reservations. That's the AI making the call about when human work gets to leave the studio. Judgment is human work. The d.school principle (keep concepts short, simple, easy to convey) survives as a reminder; the tool that automated the judgment does not. Gone.
Pitch. Took your idea and your tacit context and produced the elevator pitch — the conviction-bearing artifact you'd otherwise spend a week writing. "AI generating the artifact that carries your conviction extinguishes the conviction." My own observation, on a 4/22 transcript, after watching myself click through five AI-generated pitches and feel nothing about any of them. Gone.
Two more tools survived but had to be rebuilt at the prompt layer (Filter → Alignment, Steal → Collaborate). Filter, before the rebuild, asked the model to issue a verdict — PASS, FRICTION, REJECT — on each How-Might-We question against a four-pillar cascade.
The verdict step was the violation. Three new tools were specified — Tacit-Context (the gate), Falsification, Friction-on-Demand — to fill the gaps the audit revealed.
That's not a failure mode. That's the design. Expect 80% deletion. Make it cheap. Build infrastructure to delete.
The corollary is that you have to know which parts are deletable and which parts are durable. In BIG Tools, the deletable parts are the tools. The durable part is the Tracker — the persistence spine that accumulates a provenance trail across every tool you ran. Tools may come and go; the trail of how you arrived at an idea has to outlive every individual instrument.
When NGT was deleted, no provenance was lost — NGT had been transient through an LLM proxy and never wrote to the Tracker. When the next Reframe variant ships, it'll write into the same Tracker the same way. The boundary stayed durable while the volatile capabilities churned.
The same logic should govern your own toolkit. Identify the parts of your idea-generation practice that are durable: the questions you keep asking, the artifacts you keep producing, the people you keep returning to. Then accept that the tools you use to enact that practice — including ours — are ephemeral. Some of them will be obsolete in a year. Plan for it.
Workshops have this property too. A single workshop is a tool. The cohort it produces is the durable thing.
Thank you for welcoming me into your cohort. I'm happy to help you build some disposable tools.